Dify知识库实践
1. 概述
dify的知识库将RAG管线的各个环节可视化了,用户可以将企业内部文档、FAQ等内容上传到知识库进行结构化处理,后续供大模型查询。
2. 什么是RAG
RAG( Retrieval Augmentation Generation) 检索增强生成,RAG做的事情就是帮助大模型临时性地获得它所不具备的外部知识,允许它在回答问题之前先找答案。
- RAG中最核心的是外部知识的检索环节;
- 相比于微调,在达到相似效果时,RAG在成本效率和实时性能上具有显著优势。而微调对数据的质量和数量要求很高。并且应用程序在使用微调模型的时候可能也需要RAG技术的支持;
- 相比于长文本,大模型在处理长文本的场景下,文本越长,检索的准确度持续下降。大模型的长文本能力和RAG刚好可以完美结合,互相弥补不足;
- dify中的知识库实际就是,将文本进行分段之后转化为向量,当用户提出相关问题时,搜索的内容会转换成向量,然后在向量数据库中搜索最相似的向量,匹配最相似的几个上下文,最后将上下文组成的 prompt 一起提供给模型。
3. 数据准备
LLM 收到用户问题后,能否精准地回答出知识库中的内容,取决于知识库对内容块的检索和召回效果。匹配与问题相关度高的文本分段对 AI 应用生成准确且全面的回应至关重要。
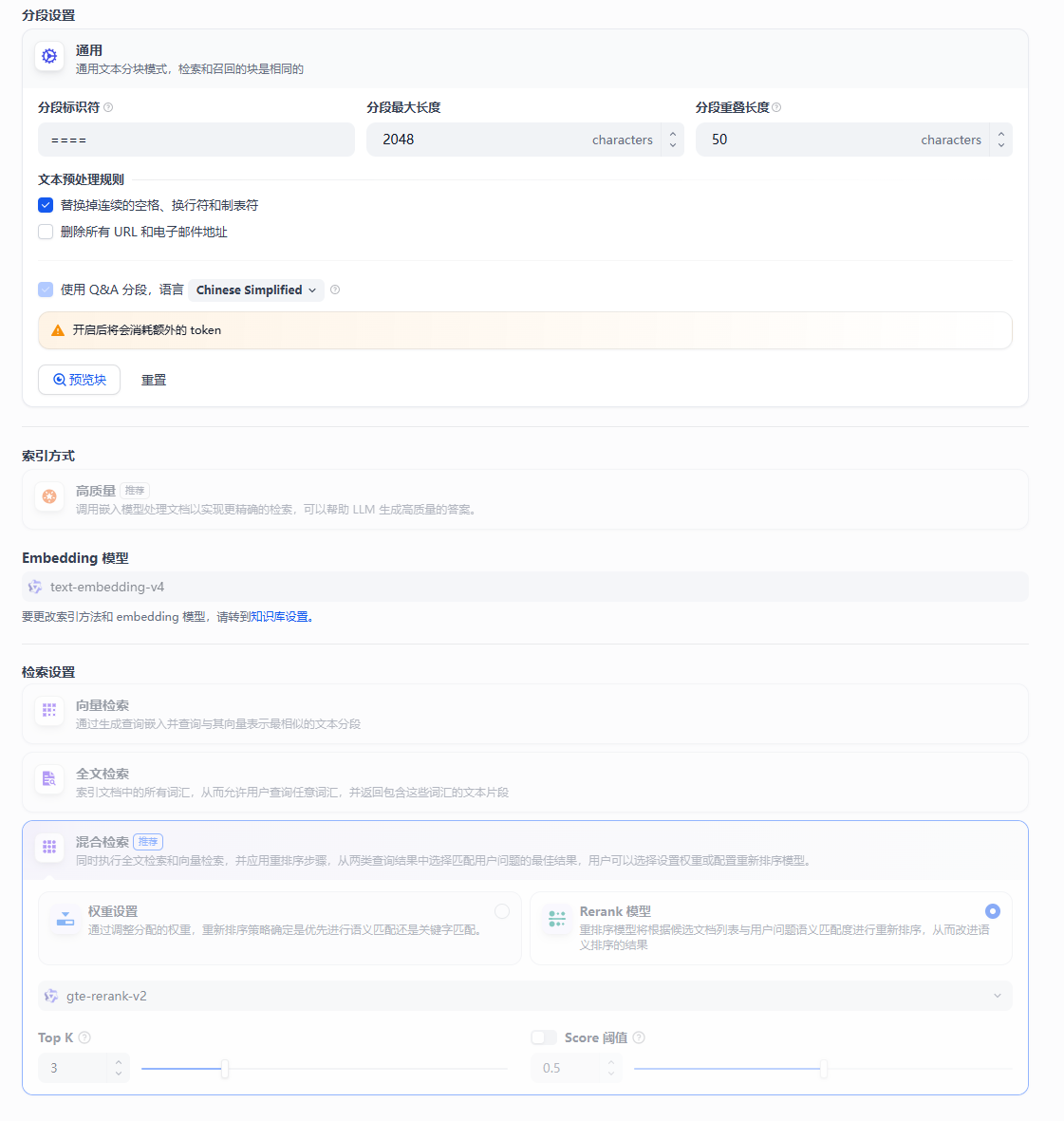
1. 分段模式
大模型的上下文窗口有限,因此需要对长文本内容进行分段。dify知识库中选定分段模式并完成知识库的创建后,后续无法变更。知识库内新增的文档也将遵循同样的分段模式。
分为通用模式和父子模式:
通用模式的分段结果为多个独立的内容分段,而父子模式采用双层结构进行内容分段,即单个父分段的内容(文档全文或段落)内包含多个子分段内容(句子)。
不同的分段方式将影响 LLM 对于知识库内容的检索效果。在相同文档中,采用父子检索所提供的上下文信息会更全面,且在精准度方面也能保持较高水平,大大优于传统的单层通用检索方式。
通用模式:系统按照用户自定义的规则将内容拆分为独立的分段。当用户输入问题后,系统自动分析问题中的关键词,并计算关键词与知识库中各内容分段的相关度。根据相关度排序,选取最相关的内容分段并发送给 LLM,辅助其处理与更有效地回答。
父子模式:与通用模式相比,父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。
父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。
eg. 在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。
基本机制包括:
- 子分段匹配查询:
- 将文档拆分为较小、集中的信息单元(例如一句话),更加精准的匹配用户所输入的问题。
- 子分段能快速提供与用户需求最相关的初步结果。
- 父分段提供上下文:
- 将包含匹配子分段的更大部分(如段落、章节甚至整个文档)视作父分段并提供给大语言模型(LLM)。
- 父分段能为 LLM 提供完整的背景信息,避免遗漏重要细节,帮助 LLM 输出更贴合知识库内容的回答。
2. 索引方法和检索方式
1. 索引方法
索引方式是否合理将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。有高质量和经济两种索引方法。
高质量:
- 使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息;使得用户问题与文本之间的匹配能够更加精准。
经济: - 每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块。
2. 检索方式
检索方式后续是可以修改的。
知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
常见的检索方式包括基于向量相似度的语义检索,以及基于关键词的精准匹配:前者将文本内容块和问题查询转化为向量,通过计算向量相似度匹配更深层次的语义关联;后者通过倒排索引,即搜索引擎常用的检索方法,匹配问题与关键内容。
高质量索引方法提供了向量检索,全文检索,混合检索三种方式;经济索引方法仅有倒排索引。
3. dify的混合检索
RAG检索的主流方法是向量检索,也就是语义相关度匹配的方式。向量检索除了能实现复杂语义的文本查找,对于相近语义的理解、多语言的理解、多模态内容的理解、模糊表述的容错性上也有优势,但是在搜索人名,物品名,缩略语,ID等效果不佳,而这正是关键词检索的优势所在。所以dify中的混合检索,同时执行向量检索和全文检索。
4. 什么是重排序
混合检索能够结合不同检索技术以获得更好的召回效果,但是不同检索方式的结果需要合并和归一化,然后再提供给大模型。所以需要引入一个评分体系,重排序模型。
重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新排序,从而改进语义排序的结果。原理是计算用户问题与每个文档的相关性分数,按照相关性从高到低排序。重排序一般放在搜索流程的最后阶段,不仅是混合检索,单一检索模式引入重排序也能改进召回效果。在具体实践中,再提交给大模型前,还会限制分段个数(也就是Top K)。
3. 小结
上传的数据在进行分段清洗后,进行embedding处理,将文本转化为向量,设置合适的检索方式,检索可以设置重排序模型,获得更好的召回效果。
4. 生产具体实践–答疑助手
1. agent提示词
1 | # Role: 日常工作智能答疑助手 |
2. 知识库配置
3. 上线后使用情况
上线一周,总计回答了4742次,共939人使用,近70%的回答内容都引用自知识库。